
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- network
- AWS
- 데이터통신
- Elk
- Static
- VCS
- Java
- redis
- git
- reactor
- javascript
- nodejs
- effective
- Lombok
- reactive
- libuv
- html
- spring
- 네트워크
- Linux
- r
- HTTP
- socket
- cache
- github
- ajax
- NoSQL
- Heap
- mybatis
- mongodb
Archives
- Today
- Total
빨간색코딩
[스프링배치 완벽가이드] 2장 스프링 배치 본문
- 참조문서

초심자의 눈으로 이해한 내용을 정리해보았다. 책에 있는 내용을 기반으로 썼지만, 책에 없는 내용도 조금씩 적어보았다. 책은 꼭 사서 보시길 바랍니다..
1. job과 step
-
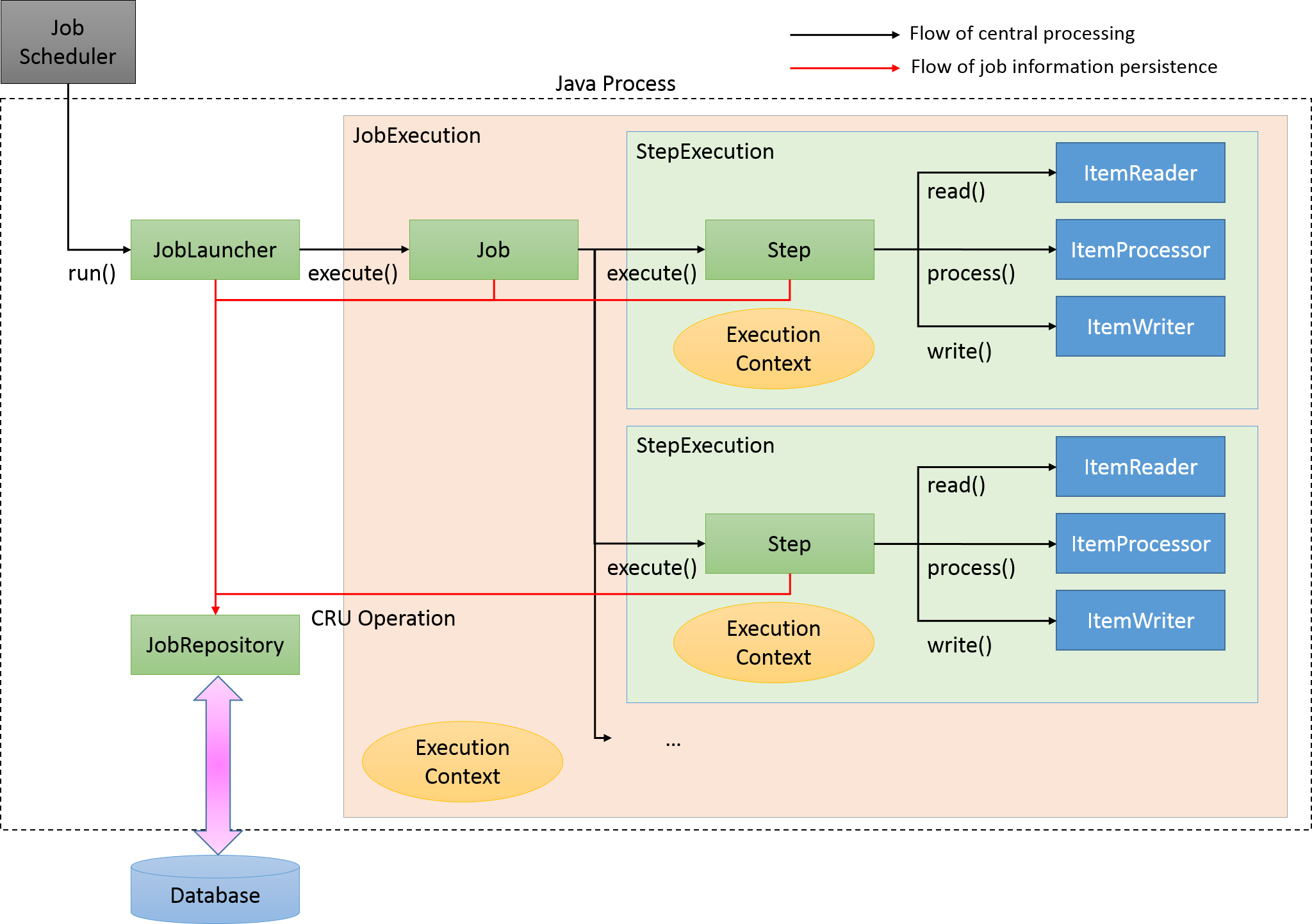
- job은 단순하게 말하면 state machine 이다.
- 현재 상태를 나타내줌
- 청크 처리, 트랜잭션 단위는 step 이다.
- job은 1개 이상의 step 으로 구성된다. (가장 작은 단위)
- step은 tasklet 기반(Tasklet 구현)과 chunk 기반(Item *)으로 나눌 수 있다.
- tasklet : execute 메소드가 호출되며, chunk 보다 간단함
- 독립적인 step을 실행할 때 주로 사용 (ex. 알림전송 등)
- ETL 패턴을 tasklet 으로 각각의 step 으로 구현한다면 메모리에 모두 올렸다가 내려야함
- chunk : commit interval 만큼 읽고 쓴다.
- ItemReader - ItemProcessor - ItemWriter
- tasklet : execute 메소드가 호출되며, chunk 보다 간단함
- 개별 step 의 독립성을 보장함으로써 얻는 이점
- 유연성
- 유지보수성
- 각 step 을 단위테스트할 수 있다.
- 재사용 가능
- 확장성 : step 병렬화
- 신뢰성 : 예외 발생 시, 해당 Item 을 retry하거나 skip 등을 할수 있음
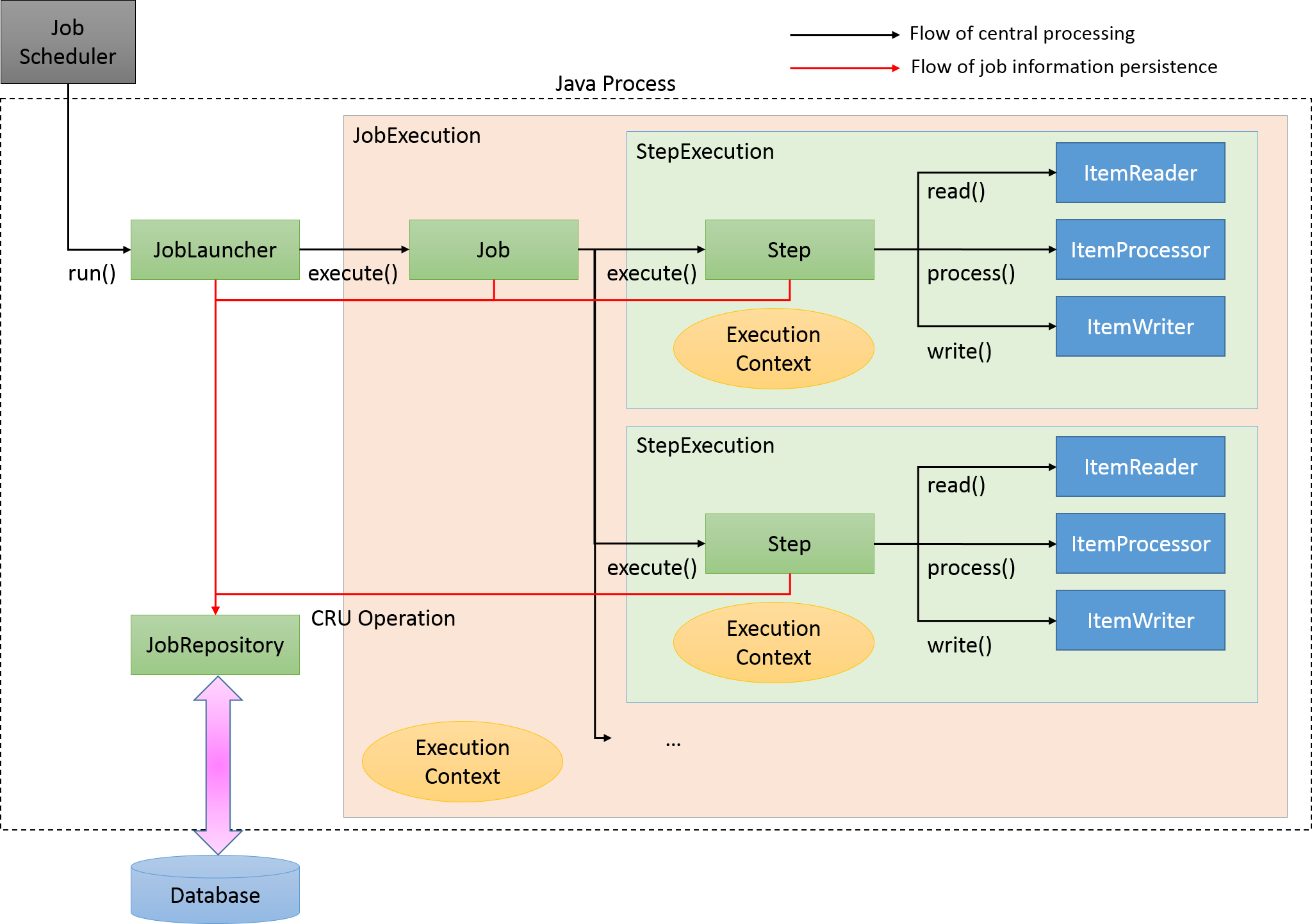
2. JobRepository
- 현재 실행중인 job의 메타정보들을 RDB에 기록
- 실행된 step, 현재 상태, 읽은 아이템, 처리된 아이템 등
- 상황에 따라 JobExecution, StepExecution 에서 상태를 갱신
3. JobLauncher
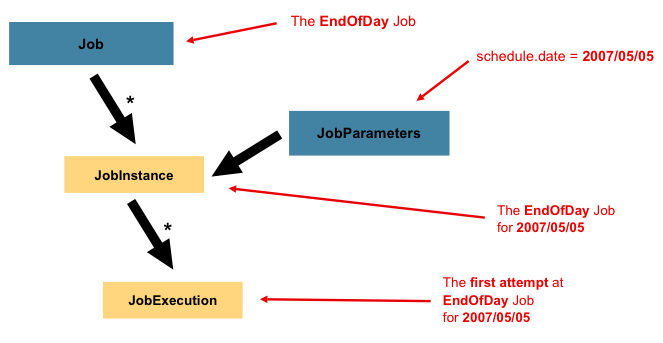
- job 실행 : job.execute
- job 의 재실행 가능여부 검증
- job의 실행방법 결정 : 현재 스레드에서 수행할지, 다른 스레드에서 실행할지
- 파라미터 유효성 검증
- cf) spring boot 는 job을 바로 실행할 수 있어서 JobLauncher 를 안 다뤄도 된다.

4. JobInstance
- job의 이름과 JobParameters의 조합으로 unique 한 인스턴스
- job이 실행될 때, 새로 생성되나, 이미 같은 조합으로 만들어진 인스턴스가 있다면, 새로 생성되지 않을 수 있다.
- ex) 실패한 job을 재실행(파라미터가 같을테니)
- 개발자가 설정을 통해 커스텀하게 unique 인스턴스 식별규칙을 바꿀 수는 있는 듯
5. JobExecution
- job의 실행에 따른 메타 데이터를 운반한다.
- job을 실행할 때마다 새로운 JobExecution 이 생성된다.
- 필드
- status : STARTED , FAILED , COMPLETED
- startTime
- endTime
- exitStatus
- createTime
- lastUpdated
- executionContext
- failureExceptions
6. 병렬화
- 가장 단순한 job 처리는 단일 스레드에서 처음부터 끝까지 처리되는 것이다.
- 그러나, 상황에 따라 병렬화해야할 수도 있다.
- 이 때, 다중스레드스텝, step병렬실행, 비동기 ItemProcessor - ItemWriter, 원격 chunk처리, 파티셔닝이 있다.
6-1. 멀티스레드로 step 실행
- 각 chunk는 트랜잭션의 단위로, 독립적으로 처리된다.
- 어떤 step 내 chunk 처리를 멀티스레드로 병렬화하는 것이다.
- step 설정에 TaskExecutor 를 지정
- 다만, thread safe 하게 Reader, Processor, Writer 가 구현되어야 함
- thread safe 하지 않다면 SynchronizedItemStreamReader 으로 감싸야함
- 단점 : chunk 처리를 병렬화하면 실패 지점에서 재시작하는 것이 불가능해짐
- 따라서 saveState 를 false로..
6-2. step을 병렬 실행
- 하나의 job에 A 스텝과 B 스텝이 서로 관련이 없다면 병렬로 처리가 가능하다.
- Split Flows 구성 : split 에 TaskExecutor 지정
- A 스텝은 A스레드가 실행, B 스텝은 B스레드가 실행
6-3. 비동기 ItemProcessor - ItemWriter
- 어떤 step 내 특정 processor 나 writer 가 병목일 수 있다.
- 이러한 경우에, 이 부분만 비동기화시킬 수 있다.
- spring-batch-integration 의존성
- AsyncItemProcessor : process 메소드가 Future 를 반환
- AsyncItemWriter : future.get 을 통해 write 처리
- 이거 안써도 되지만, future 를 직접 다뤄야함
- 결국, 특정 처리단위를 다른 스레드에 물리는 꼴이라, 특정 단위의 병목 상황에만 고려해볼만 하겠다.
- 스레드 단순 스위칭을 통한 스레딩모델은 최근 리액티브스트림 진영에 의해 대체되고 있는 추세인데, 이 AsyncItem* 도 마찬가지이겠다.
- 배치의 특성과 맞물려 재밌는 논의들이 있는데..
- https://github.com/spring-projects/spring-batch/issues/1008
- 요약하면 유한의 데이터를 다루는 chunk지향 처리의 배치 패러다임에서 리액티브 스트림의 무한데이터는 다루는 대상부터가 잘못되었다는 이야기다.
- (배치 코어를 아예 다시 작성해야한다는 것도..)
6-4. 원격 chunk 처리
- 위의 3가지가 단일 jvm 에서 스레딩을 통한 병렬처리였다면, 6-4번과 6-5번은 분산노드 처리이다.

- master 노드에서 read한 Item을 메세지가 유실되지 않는 미들웨어(ex. MQ)를 통해 slave 노드에 전송하고, slave 노드에서 Processor (또는 Writer까지) 를 처리하는 방식이다.
- 처리는 slave에서 하더라도, 완료여부를 master 에게 계속 알려주며 통신해야해서, 네트워크 통신량이 많을 수 있다.
- 이미 존재하는 Processor, Writer 를 활용할 수 있는게 장점
- 코드변경이 별로 없음

6-5. 파티셔닝

- 6-4번과의 차이
- 코드 작업이 꽤 필요 (partitionHandler 등)
- 메세지가 유실되지 않는 미들웨어(ex. MQ)를 사용하지 않아도 됨
- 마스터 노드가 워커의 스텝 수집을 위한 컨트롤러 역할만 함
- 워커의 step은 독립적으로 동작하며 각각 별도로 StepExecution 을 갖는다.
- StepExecution 을 별개로 가지므로, JobRepository 에 메타데이터들을 저장할 수 있게되고, MQ가 필요없어진 것이다.
- 로컬 파티셔닝
- 멀티스레드로 동작
- 6-1번과 비슷해보이나, 6-1번은 StepExecution 이 하나다. (가장 큰 차이점)
- 따라서, Reader 등의 thread safe 여부가 중요치 않다.
- 원격 파티셔닝
- 분산된 노드에서 동작

7. Hello World!
- 의존성
- spring-boot-starter-batch
- spring-boot-starter-jdbc
- h2
- @EnableBatchProcessing : 배치 인프라스트럭처를 부트스트랩하는 데 사용한다. 따라서 개발자는 바로 bean 을 주입받아서 사용이 가능하다.
- JobRepository
- JobLauncher
- JobExplorer : JobRepository 위에서 readonly 만 수행
- JobRegistry : 특정한 Launcher 구현체를 사용할 때, job 을 찾는 용도
- PlatfromTransactionManager : job 실행 전반에서 트랜잭션을 관리
- JobBuilderFactory
- StepBuilderFactory
- Step 구성
-
@Bean public Step step() { return this.stepBuilderFactory.get("step1").tasklet(new Tasklet() { @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { System.out.println("hello world!"); return RepeatStatus.FINISHED; // CONTINUABLE 을 반환하면 다시 execute가 호출된다. } }).build(); } - Job 구성
-
@Bean public Job job() { return this.jobBuilderFactory.get("job").start(step()).build(); } - 스프링 부트는 ApplicationContext 내 모든 job 을 구동될 때 실행하므로, run 만해주면 실행된다.
- 내부적으로 스프링부트 autoconfigure의 BatchAutoConfiguration가 JobLauncherApplicationRunner 를 생성한다
- 책에서는 JobLauncherCommandLineRunner 를 이야기하고 있지만, 2.3.0 부터 deprecated 되었다.
- https://github.com/spring-projects/spring-boot/issues/19442
- CommandLineRunner 를 구현하던 것에서 ApplicationRunner 를 구현하는 쪽으로 변경
- -- 같은 것도 raw String 으로 취급되어 넘어온게 거슬렸던 듯..?
- JobLauncherApplicationRunner 가 실행되지 않게하려면 spring.batch.job.enabled=false 를 설정해줘야 한다.
- JobLauncherApplicationRunner 은 jobNames 이 없다면 등록된 job을 반복문을 수행하며 일괄 실행한다.
- cf) jobNames 관련해서는 N개 지정 실행을 더이상 지원하지 않는 쪽으로 논의가 되고있나보다.
- 내부적으로 스프링부트 autoconfigure의 BatchAutoConfiguration가 JobLauncherApplicationRunner 를 생성한다
'Spring' 카테고리의 다른 글
| Spring Data JPA 살펴보기 (JpaRepository, Bean으로 만들어지는 원리, 메소명으로 쿼리 만들기) (0) | 2022.01.05 |
|---|---|
| [스프링배치 완벽가이드] 1장 배치와 스프링 (0) | 2021.08.18 |
| Spring Event와 SSE 로 리액티브하게 접근하기 (EventListener, Server-Sent Events, 비동기 컨트롤러, RxJava로 동일하게 재구현) (1) | 2020.12.31 |
| Reactive와 Spring 4 (C10K, 리액티브 선언문, 리액티브 스프링 등장 전) (0) | 2020.12.30 |
| spring webflux와 armeria 살펴보기 (Mono, Flux, gRPC, Thrift) (0) | 2020.06.19 |
'Spring' Related Articles
more




Comments