
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- VCS
- Linux
- 네트워크
- redis
- github
- javascript
- Lombok
- Static
- socket
- libuv
- effective
- git
- mongodb
- reactive
- network
- nodejs
- ajax
- spring
- 데이터통신
- AWS
- cache
- mybatis
- NoSQL
- r
- reactor
- Java
- Elk
- html
- HTTP
- Heap
Archives
- Today
- Total
빨간색코딩
JPA란 무엇인가 (Before JPA, 영속성 컨텍스트, Entity, JPQL, 트랜잭션, N+1 문제) 본문
- 참조문서
1. JPA 란?
- Java Persistence API 의 약자로 java진영의 ORM 표준스펙이다.
- 높은 생산성을 가져다주며,
- 동아시아(한중일)를 제외하고는 Data Access 레이어에 JPA를 대부분 사용중
- JPA는 이미 검증된 기술
1-1. Before JPA
- JDBC
- Spring JdbcTemplate
- iBatis, MyBatis
- 장점
- JDBC를 좀 더 편하게 사용할 수 있도록, 객체를 메소드(=SQL)와 맵핑함 (JPA는 테이블과 맵핑)
- SQL Mapper 이며 단순하면서도, SQL을 직접 다루어서 강력함
- 소스코드와 SQL을 분리
- 단점
- 반복적인 코드, SQL을 개발자가 직접 작성
- SQL과 DBMS 벤더에 종속성
- 장점
1-2. 역사
- 하이버네이트가 먼저 만들어짐
- java 진영에서 하이버네이트를 기반으로 JPA 명세 작성
- Hibernate (de facto)
- EclipseLink
- DataNuclues
- JPA 1.0 (JSR 220, 2006년) : 초기버전, 복합 키와 연관관계 기능 부족
- JPA 2.0 (JSR 317, 2009년) : 대부분의 ORM 기능 포함, JPA Criteria 추가
- JPA 2.1 (JSR 338, 2013년) : 스토어드 프로시저 접근, 컨버터, 엔티티 그래프 기능이 추가
1-3. 단점
- 높은 학습 곡선
- JPQL의 한계
- ex) 인라인뷰
- 다만, Native SQL 작성 지원
- CQRS(커맨드와 쿼리를 분리)로 극복 가능 등
2. JPA를 사용하지 않았을 때 (JPA의 필요성의 대두)
- SQL 위주의 반복적인 개발
- 개발자가 코드수정시 항상 SQL 맵퍼적인 작업까지 해줘야함
- ex) 필드 추가 시 SQL 모두 수정필요
- 특정 벤더, DBMS 에 강결합
- ex) 페이징 처리시 Oracle은 ROWNUM, MySQL은 LIMIT 등
- 객체와 RDB의 차이에 따른 제약
- 상속
- 생성 : RDB는 INSERT를 두번 쳐야함
- 조회 : 1대1 JOIN을 통해 구현
- 위 SQL들이 복잡해지다보니, RDB에서 상속구조를 잘사용치않고 풀어써버림
- 연관관계
- JOIN을 통해 표현 가능하나, RDB table에는 FK 칼럼만 있음
- 보통, 객체모델에 이 FK 칼럼명으로 필드를 선언함
- 즉, 객체를 테이블에 맞춰서 모델링하게 됌
- 객체 그래프
- 객체 모델이 정의되어있어도, SQL 로 Select 해서 채우지않는다면, null 이 들어있음. 엔티티 신뢰의 문제
- 데이터 타입
- 상속
- 결론적으로, 객체답게 모델링할 수록, SQL 맵핑작업이 매우 늘어나게 된다.
3. JPA의 내부 동작 방식
3-1. JPA는 JDBC API를 사용

3-2. 영속성 컨텍스트
- 엔티티를 영구 저장하는 환경이며, 엔티티 매니저를 생성할 때, 하나만 만들어진다.
- 즉, 엔티티 매니저를 통해서만 접근과 관리가 가능
- Map<Id, Entity> 으로 관리
- 엄밀하게 말하면 entityManager.persist(member); 를 실행하면, DB에 저장하는게 아니라 영속성 컨텍스트에 저장한다
- 트랜잭션이 커밋되는 시점에 DB로 쿼리가 날라가는 것. (flush 된다고 함)
- 엔티티의 생명주기
- 비영속(new/transient): 영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
- 영속(managed): 영속성 컨텍스트에 관리되는 상태
- 준영속(detached): 영속성 컨텍스트에 저장되었다가 분리된 상태
- 삭제(removed): 삭제된 상태
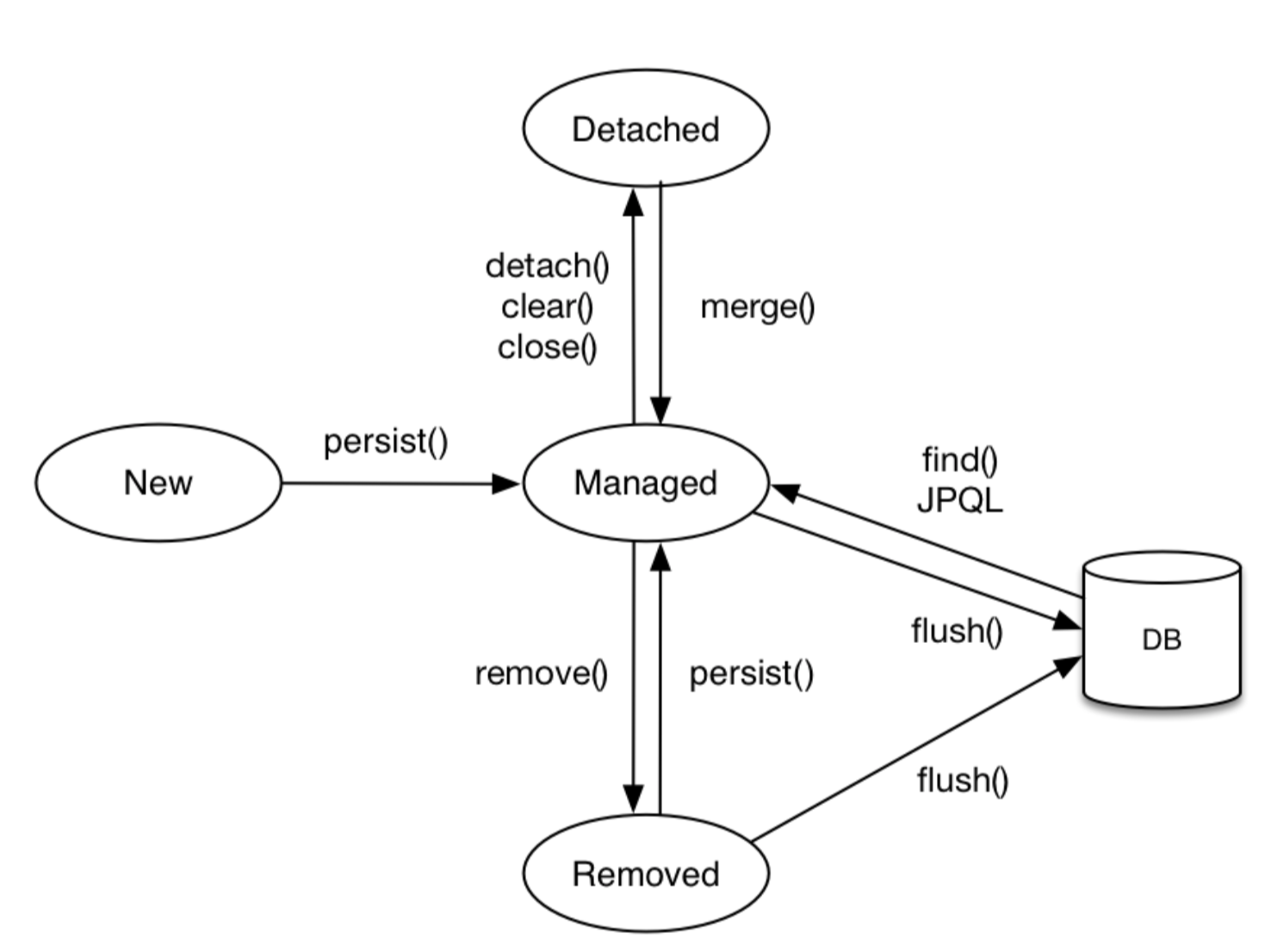
- 엔티티의 생명주기에 따라 특정 이벤트를 처리하기
- 리스너나 어노테이션 등록
- https://www.baeldung.com/jpa-entity-lifecycle-events
- @PostLoad, @PrePersist, @PreUdate, @PreRemove, @PostPersist, @PostUpdate, @PostRemove엔티티의 생명주기
- 영속성 컨텍스트가 있음으로서 얻는 장점
- 1차캐시와 동일성(identity) 보장
- 동일한 트랜잭션에서 조회한 엔티티는 같음을 보장한다. member1 == member2
- DB Isolation Level 이 Read Commit 이어도, 어플리케이션에서 Repeatable Read 보장
- 트랜잭션을 지원하는 쓰기 지연
- 트랜잭션 커밋할때까지 버퍼에 INSERT 쿼리 모았다가 배치 전송
- UPDATE, DELETE 은 row lock 최소화하는 효과
- 변경 감지(Dirty Checking)
- setter 로 엔티티모델이 수정되면, 컨텍스트 내 스냅샷과 비교해보고, flush 될때 update SQL 로 실행
- 변경된 필드만 update set 하지는 않고, 전체 필드를 update한다.
- 장점 : 쿼리 재사용
- 단점 : 네트워크 전송량은 증가
- 영속 상태의 엔티티에만 적용된다.
- 지연 로딩과 즉시 로딩
- 지연로딩 : 객체가 실제 사용될 때 로딩
- ex) member.getTeam().getName(); // name 을 참조할 때, SELECT * FROM TEAM 쿼리 전송
- 즉시로딩 : JOIN SQL 로 한번에 연관된 객체까지 미리 조회
- 상황에 따라 옵션을 통해 조정가능
- 지연로딩 : 객체가 실제 사용될 때 로딩
- 1차캐시와 동일성(identity) 보장
3-3. flush
- 영속성 컨텍스트의 변경 내용을 DB에 반영한다.
- flush 된다고, 영속성 컨텍스트를 비우지는 않는다. 동기화시키는 것 뿐
- flush 의 실행순서
- 변경감지가 동작하여 스냅샷과 비교하여 수정된 엔티티를 탐색
- 수정된 엔티티는 update sql 을 만들어서 SQL저장소에 등록
- SQL저장소에 있는 insert, update, delete 쿼리들을 DB로 전송
- flush 를 수행하는 방법
- flush() 메소드 실행
- commit 하면 자동 호출됨
- jpql 쿼리 실행
- FlushModeType
- AUTO : 커밋이나 쿼리(jpql)할 때 실행
- COMMIT : 커밋할 때만 실행
3-4. 2차 캐시
- 어플리케이션 범위의 캐시
- 1차캐시 조회 시 없으면, 2차캐시를 조회하게된다. 기본 키를 기준으로 캐시한다.
- 동시성 이슈때문에 항상 복사본을 반환해준다.
- 영속성 컨텍스트가 다르면, 객체동일성을 보장하지 않는다.
- provider 로 ehcache, redis 등을 사용 가능
- SharedCacheMode 설정
- ALL : 모든 엔티티를 캐시
- NONE : 캐시 사용안함
- ENABLE_SELECTIVE : Cacheable(true)로 설정된 엔티티만 캐시를 적용
- DISABLE_SELECTIVE : 모든 엔티티를 캐시하는데 Cacheable(false)로 설정된 엔티티만 제외하여 캐시함
- UNSPECIFIED : JPA 구현체가 정의한 설정에 따름
4. Hello World!
4-1. 설정 관련
- dialect 설정
- JPA는 특정 벤더, DBMS에 종속되지 않음
- 그러나, 각각의 DBMS가 제공하는 SQL 문법과 함수가 조금씩 다름
- 가변문자 데이터타입 : MySQL 은 VARCHAR, Oracle 은 VARCHAR2
- 따라서, 구현체가 맵핑해놓은 dialect 를 설정하여 특정 DBMS의 고유한 기능들을 이용
- org.hibernate.dialect.MySQL5InnoDBDialect
- hibernate는 40여가지를 지원
- JpaTransactionManager
- MyBatis에서는 DataSourceTransactionManager 를 사용했으나,
- JPA 에서는 자체 트랜잭션 매니저 사용
4-2. 핵심 코드
EntityManagerFactory emf = Persistence.createEntityManagerFactory("unit명"); // 어플리케이션 당 1개만 존재
EntityManager em = emf.createEntityManager(); // thread-safe 하지 않음 (한번쓰고 버려야함)
EntityTranscation tx = em.getTranscation(); // 모든 데이터 변경은 트랜잭션 안에서 실행해야함
tx.begin();
// 비즈니스 코드
tx.commit();
em.close()
emf.close();4-3. EntityManagerFactory
- EntityManager 를 생성하는 Factory 다.
- MyBatis 에서의 SqlSessionFactory 에 해당한다.
- 어플리케이션 전체에서 하나만 생성해서 공유해야한다.
- Persistence 를 통해 생성가능
- Persistence.createEntityManagerFactory("unit명");
4-4. EntityManager
- 내부적으로 DB커넥션을 물고 동작한다.
- MyBatis 로 치면, SqlSession 이다.
public interface EntityManager {
public <T> T find(Class<T> entityClass, Object primaryKey);
public void persist(Object entity);
public <T> T merge(T entity);
public void remove(Object entity);
// 생략...
}4-5. CRUD
- 저장: jpa.persist(member)
- 조회: Member member = jpa.find(memberId)
- 수정: member.setName("devljh")
- 삭제: jpa.remove(member)
5. Entity
- Entity : JPA를 이용해서 DB 테이블과 맵핑할 클래스
5-1. 엔티티 모델 어노테이션
5-1-1. 기본
- @Entity : JPA가 관리할 객체임을 명시
- 기본생성자가 필수로 필요함
- @Table : 맵핑할 DB 테이블 이름을 명시
- @Id : 기본 키(PK)
- @GeneratedValue : 기본 키 맵핑 전략
- strategy : 자동할당
- TABLE : 채번 테이블을 사용
- SEQUENCE : DB 시퀀스를 사용
- IDENTITY : DB에 위임
- AUTO : 설정된 Dialect 에 따라 자동 선택 (MySQL은 IDENTITY, Oracle은 SEQUENCE)
- generator : 직접할당
- strategy : 자동할당
- @Column : 필드와 칼럼을 맵핑
- name : 칼럼명
- nullable : NOT NULL 여부
- unique
- updatable
- @Temporal : 날짜 타입 매핑
- DATE : 날짜만
- TIME : 시간만
- TIMESTAMP : 날짜+시간
- @Transient : 특정 필드를 칼럼에 맵핑하지 않음
5-1-2. 복합키
- 복합키 설정 방식 2가지
- @IdClass
- Entity 레벨에서 선언
- 필드레벨에서는 @Id N개 선언
- @EmbeddedId
- 필드 레벨에서 선언
- 복합키 클래스에 @Embeddable 선언
5-1-3. 외래키(FK)
- @JoinColumn
5-1-4. 연관관계 설정, 다중성
- @OneToOne : 일대일(1:1)
- @OneToMany : 일대다(1:N)
- 설정가능한 옵션들
- Class targetEntity() default void.class;
- CascadeType[] cascade() default {};
- FetchType fetch() default LAZY;
- String mappedBy() default "";
- boolean orphanRemoval() default false;
- @ManyToOne : 다대일(N:1)
- @ManyToMany : 다대다(N:M)
5-2. 연관관계
5-2-1. 방향성
- 단방향
- 양방향
- 관계의 주인 설정 필요
- 연관 관계의 주인은 외래 키(FK)가 있는 곳
- 연관 관계의 주인이 아닌 경우, mappedBy 속성으로 연관 관계의 주인을 지정해야함
- 관계의 주인 설정 필요
- cf) 단방향으로 설정하는 것을 권장
- 양방향으로 설정 시, 고려할 부분이 많아짐. (양방향은 디펜던시 사이클 등의 문제가 있음)
5-2-2. 영속성 전이(CascadeType)
- 연관 관계가 설정된 Entity 간, 영속성 전이를 설정할 수 있음
- ALL : 모든 변경 상황에, 하나의 엔티티가 변경되면 연관관계에 있는 다른 엔티티도 변경된다
- PERSIST
- MERGE
- REMOVE
- REFRESH
- DETACH
5-2-3. Fetch Startegy
- 하나의 Entity 가 로딩될 때, 연관 관계가 있는 다른 Entity 의 로딩 전략을 설정할 수 있음
- EAGER : 즉시로딩
- LAZY : 지연로딩 (default)
5-3. 스키마 자동생성
- hibernate.hbm2ddl.auto 속성
- 개발장비에서만 사용할 것, 운영장비에서는 위험하다.
6. JPQL (Java Persistence Query Language)
- 참조문서
- 테이블이 아닌 엔티티 객체를 대상으로 검색하는 객체지향 쿼리
- SQL을 추상화해서 특정 데이터베이스의 SQL에 의존하지 않음
- JPA는 JPQL을 분석한 후, 적절한 SQL을 만들어서 DBMS에 질의
- Dialect 만 수정해주면 됨
6-1. 문법 메모
- Select
- 테이블명 대신 엔티티명(@Entity(name="엔티티명"))을 사용
- 별칭 필수
6-2. fetch join
- 일반조인과 페치조인의 차이점
- https://stackoverflow.com/questions/17431312/what-is-the-difference-between-join-and-join-fetch-when-using-jpa-and-hibernate
- 페치조인은 연관관계까지 고려하여 select 절 작성
- 일반조인은 연관관계를 고려하지 않고 select 절이 작성되기 때문에, 컬렉션이 채워지지 않게되며, null 이기 때문에 추가로딩이 발생함
7. 트랜잭션
7-1. 낙관적 Lock
- 엔티티 모델에 버전 필드를 만들고 @Version 선언
- 최초에 0으로 초기화되며, 변경이 있을때마다 1씩 증가
- 엔티티 수정 시, 조회 시점의 버전과 수정 시점의 버전이 다르면 OptimisticLockException 발생
7-2. 비관적 Lock
- DBMS의 트랜잭션 락 매커니즘에 의존
- ex) select for update
8. 설계 시 참고할 것
8-1. N+1 문제
- 원인 : A엔티티를 조회하는데, A가 List<B>를 갖고있어서, B를 즉시 또는 지연 로딩해오는데, N회 쿼리가 발생함. 즉, N+1 회 쿼리 발생
- 해결
- 하이버네이트 @BatchSize : 지정한 size만큼 SQL의 in절을 이용해서 한번에 조회한다.
- 단점 : 패치전략의 변경, size 정적 고정
- 조인을 사용 : 페치 조인을 사용하면 연관관계를 함꼐 조회함
- 단점 : 페이징API 사용불가능, 두개이상의 컬렉션부터는 페치 조인 불가능 (MultipleBagFetchException)
- 하이버네이트 @BatchSize : 지정한 size만큼 SQL의 in절을 이용해서 한번에 조회한다.
8-2. 도메인 모델과 엔티티 모델의 분리
- 엔티티 모델은 JPA의 어노테이션들이 붙을 수 밖에 없음
- 도메인 모델은 가능한 모든 기술로부터 독립되는 것이 이상적
- 엔티티모델에서 to도메인모델() 같은 메소드를 통해 변환메소드 제공
- 엔티티 모델을 그대로 사용할 경우, 컨트롤러, 뷰 레이어까지 트랜잭션이나 지연로딩 등을 활용할 순 있으나, 권장하진 않음.
- 1안) OSIV(Open Session In View)을 false로 설정하자
- 2안) DTO 로 분리
'Java' 카테고리의 다른 글
| Reactor 의 탄생, 생성과 구독 (역사, Publisher 구현체 Flux와 Mono, defer, Subscriber 직접구현) (0) | 2021.01.18 |
|---|---|
| RxJava 코드로 Reactive Streams 맛보기 (코드레벨의 동작방식, map, filter, reduce 연산자 직접 구현) (0) | 2020.12.31 |
| Reactive Streams (관찰자 결합, 반복자 결합, Back Pressure, 흐름, Processor, 비동기 및 병렬화 구현방식) (0) | 2020.12.31 |
| Enum 찾기의 달인 (효율적으로 찾기, spring bean과 맵핑) (0) | 2019.12.13 |
| [이펙티브 자바3판] 7장 람다와 스트림 (0) | 2019.01.18 |
'Java' Related Articles
more




Comments