| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- mybatis
- libuv
- 네트워크
- spring
- r
- redis
- VCS
- ajax
- network
- 데이터통신
- nodejs
- Heap
- HTTP
- reactive
- cache
- Java
- AWS
- Elk
- Static
- mongodb
- html
- Lombok
- github
- socket
- effective
- javascript
- Linux
- NoSQL
- git
- reactor
- Today
- Total
빨간색코딩
구조체의 메모리 저장방식 본문
구조체의 메모리 저장방식을 알면 멤버변수들을 선언할때 좀 더 메모리를 효율적, 최적화되게 쓸 수 있다.
1. 구조체의 바이트 패딩
바이트패딩이란 멤버 변수를 메모리에서 CPU로 읽을 때 한번에 읽을 수 있도록, 컴파일러가 레지스터의 블록에 맞춰 바이트를 패딩해주는 최적화 작업이다. 만약 컴파일러가 패딩을 하지 않는다면(=최적화를 해주지 않는다면) CPU가 메모리에 다시 접근하면서 성능이 떨어질 것이다.
struct x {
char a;
int b;
char c;
};
struct x data;
위 구조체를 sizeof(data) 로 찍어보면 6이 나올 것같지만 12가 나온다. 컴파일러는 구조체를 구성하는 멤버들을 가장 크기가 큰 멤버 자료형의 배수가 되도록 정렬한다. 이 정렬을 위해 의미없는 바이트(패딩)들을 붙이는 것이다. 따라서, 위 코드에서 컴파일러는 4바이트의 int형에 맞춰 멤버들을 정렬한다. 암묵적으로 a와 c 뒤에 3바이트씩의 패딩을 추가시켜주는 것이다.
struct x {
char a;
char b;
char c;
};
위 구조체는 3바이트다. 가장 큰 멤버의 자료형의 배수 = 1바이트니까~~
struct x {
char a;
char c;
int b;
};
struct x data;
위 구조체는 sizeof(data)로 찍으면 12가 아니라 8이 나온다. 이해를 돕기위해 그림을 그려보면

이런식으로 되는 것이다. 즉, 구조체의 메모리 저장방식을 알게되면 효율적으로 구조체 멤버를 선언할 수 있다!!
2. 전처리기 #pragma pack(n)
참조문서: https://msdn.microsoft.com/ko-kr/library/2e70t5y1.aspx
이 전처리기는 정수 n값이 넘을 경우, 정렬(=패딩 바이트 추가)을 포기한다는 거다. 즉, n값이하일 경우에만 정렬하려고 한다. n값은 1,2,4,8,16 만 유효하다. 이 전처리기를 쓰지 않았을 경우 디폴트값(n)은 8이다. 8바이트인 이유는 64비트 운영체제여서가 아니라 기본 타입중 가장 큰 타입이 8바이트이기 때문이다. 만약 int128_t같은걸 쓰는 시대가 온다면 16바이트로 바뀔 수도 있겠다.
#pragma pack(1)
struct x {
char a;
int b;
};
struct x data;
위 구조체의 sizeof(data)의 값은 5이다. 최고 크기가 4바이트이지만 전처리기에서 1바이트가 넘으면 정렬하지 않겠다고 했기 때문이다. 따라서 바이트 패딩이 일어나지 않는다.
'C' 카테고리의 다른 글
| 아두이노 Digita I/O & Analog I/O (0) | 2017.04.02 |
|---|---|
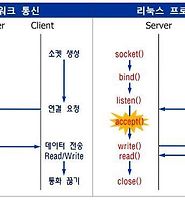
| TCP소켓 Half-close 기법 (0) | 2017.03.28 |
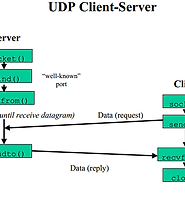
| (UDP소켓 프로그래밍) socket.h API, connected UDP소켓 (0) | 2017.03.27 |
| 표준 스트림 (표준출력과 표준오류의 차이) (0) | 2017.03.22 |
| (TCP소켓 프로그래밍) socket.h API, 네트워크 바이트 순서 (0) | 2017.03.14 |